The Carpentries lessons are a very useful resource for any researcher around the world, a proof of that is how popular software and data carpentries workshops have become! I’ve been part of this community since 2012, and soon after that some of us started to think on translations (probably there were others before us!). At that time all the lessons were in a single repository (you can still find it), and the way we started to translate the lessons into Spanish (check our PRs) was to keep track of our original files by adding a comment with the hash of the version of the original file. We didn’t got too far. The main problem being the time that all of us could commit to this. In parallel there was also Raniere translating it into Portuguese.
However… much has changed since 2014! Now there’s a repository for each lesson, the lessons are written in markdown and the community has grown a lot!
Since last summer there’s been a strong push by many on latinoamerica, and they’ve got a lot done! They have organised amazingly well, creating a glossary and style, a mailing list and get a bunch of dedicated volunteers! (67 members on the mailing list, and roughly counting more than 20 that have contributed to the translations on github!).
When talking about translations there are two main models one can follow, let’s call them upstream and wikipedia. There are probably more models, but I thing these are the two that needs an attention in this project. With upstream I am referring to a project that originates in a language, and the translations follow that. Think it as a book - El Quijote was written in Spanish and many translations appeared from it. There’s no way a translation will feed the author of the book to improve something. Another example is the menus and guides on software tools. If you use Firefox in Italian the words are translated from the English - there’s no a new functionality coming from the translation that needs to be brought into the upstream version. On the other hand, wikipedia has a translation of pages that are diverging. Some article may have been created in Tamil and someone translated into Turkish and then other contributors have added more information on the Turkish than what it was on the original Tamil article. However, another wikipedia editor may add these bits back into the original.
In the first case it’s very simple to track what’s been translated and what’s not, also, if something changes upstream, it’s easy to track too. On the wikipedia case it’s impossible (or almost impossible) to track - the articles become rapidly different enough to be considered a translation of the original. (And in a way that’s the beauty of wikipedia, right?)
What’s best for the Carpentries? Probably an hybrid between both. Anyone can contribute to the English lessons via a pull request, as for any software project. In the same manner the community can provide comments and suggestions via GitHub and the maintainers have the last power to decide what to merge and what not. If we have lesson A and lesson A-es, then similar process occur, and that’s great to fix translations, typos and similar “minor” changes. But what happens if the “es” community finds out about a better flow to teach a lesson? If such new approach can be generalised to other cultures then probably it could be brought up for discussion upstream and then after approval implement it in all the translated lessons (A-es, A-it, A-gr, …). However, if such change doesn’t make sense to other cultures then we have a diverging point. If it’s a simple change on the order on how something is taught (A.2 before A.1) probably we have the means to keep track of that, though if it’s something more intrinsic… then I don’t know what could be done.
What’s done now?
At the moment the lessons at the carpentries are “forks” (imported) of the style lesson. This workflow is well explained at the documentation (look at the diagrams!). In a similar manner, the translated lessons are imported from the original. The maintainer of the translated lesson will pull from upstream (the English one) and that will show the changes that need to be translated (probably as merge conflicts - though I’ve not suffered that myself yet).
On the other side, the translators take the original files and start translating them on the text editor. Sentence by sentence. When completed they make a pull request to the A-es repository, reviewed and finally merged.
What am I proposing?
Translations are hard! Mostly because you need to keep a flow and consistency over a text. You need to keep your glossary at hand and keep a track of what changes upstream without the need to re-read the whole text again to know where the new change belongs.
Thing is that we are not alone! Translations have been a common practice in many areas before. From legal documents on countries with more than an official language and companies that expand internationally to software used by many. We have to learn from them that have been doing it for decades. Many open source communities have created glossaries and style guides for their documentation (e.g., Gnome’s) and there are lots of tools to make the translation process easier and better to track.
The main tools used to translate (interfaces and documentation) by many software groups are based on gettext and PO files. These tools tokenise code or text and keep track of what happens to them. If in a new version only one token changes the special text editors (e.g., PoEdit, GTranslator, Lokalize) will show what needs to be updated. There’s other projects like Translate toolkit that offers lots of tools to work with these type of files.
Using these tools we could keep a track of what’s been translated, what’s new, find where we need help and visualise all that in a simple dashboard.
During the hack-day at the last Collaborations Workshop I tackle more of less of what’s need be done in terms of infrastructure. However, to make it work properly we would need some structure (again, imitating of what I learn from translators from Gnome).
- Lessons release calendar. That helps translators to schedule time to focus on the translations of the lesson.
- Have an editor (or few) for each language - similar role than the maintainer.
- Main maintainer (English) don’t need to know about the languages as they may have been approved by the editors.
- Glossary and writing style guides.
In the model I built (see figure below) I depend on two things.
The first is that each lesson would use submodules to bring in the translations.
That will make the url of the lessons something like: lesson/<lang>/index.html
where <lang> is the language code.
The second is to use Travis-ci to generate a dashboard with the translations
progress for each lesson and each language and to generate the markdown files
based on the po translated files and push them to the respective repository.
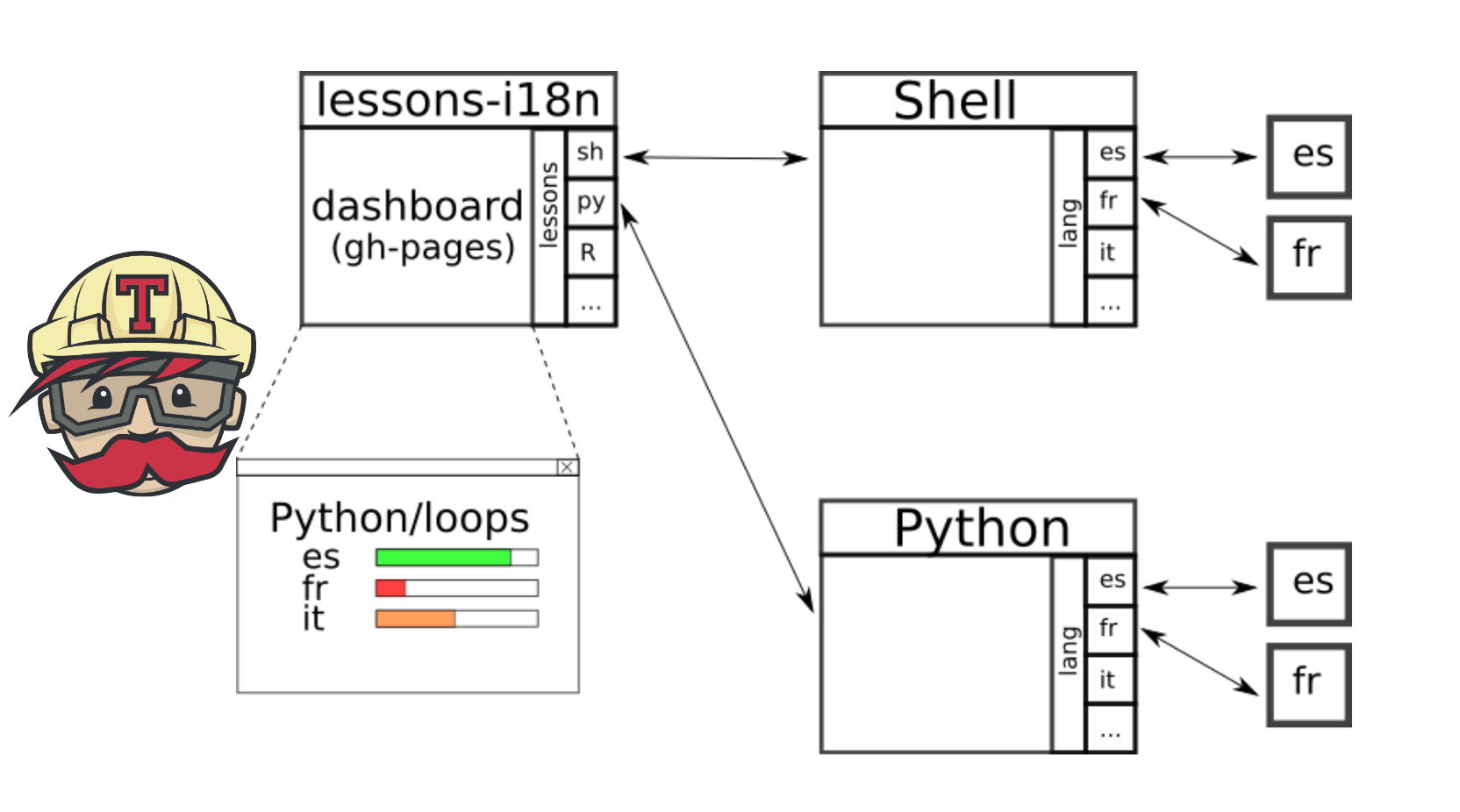
Each box represents a repository and the arrows are the connections as submodules between them. Travis would be in charge of making a dashboard and create and update the repositories with new translations.
What have I got so far?
In this test GitHub organisation I’ve got the markdown to po tool that I have adopted and modified so it works with the carpentries material. A central i18n repository where all the magic happens - keeps track via submodules of the upstream repositories and generates a gh-pages with a dashboard of what’s been done (still very crude).
What’s still needed?
To make the whole thing to work I still need certain things to work. These includes write tests, get Travis to generate the stats and new repositories and even a bot that analyses your PRs before they are merged (like pep8speaks or codecov reports)
What problems could this bring?
Translators will need to become familiar to use the po format. The good news is that there are plenty of tools that shows that in a nice way. However it is a tool to learn - whereas now they can just use a text editor. I think the advantages that these tools bring worth the learning.
Also this needs a change on how all the lessons are maintained. Will this be very disruptive to how are things now? I don’t think so, but this is why I’m trying this in a different set of repositories so I could show how everything works (if it does!).
More thoughts
While learning how everything “hangs” from the styles repository I’m thinking into convert that as a jekyll theme now that github allows to use them from github repositories. That would remove the task on the maintainers to keep up to date with the styles.
